Tensorflow Autoencoders 튜토리얼을 학습하고, RGB 이미지를 압축하는 데모 페이지를 제작해보려고 한다. 머신러닝을 처음 접해보기 때문에 개념 접근을 우선으로 했으며 아래 링크에 정리해두었다.
Tensorflow에서 제공하는 튜토리얼 코드를 기반으로 한다. 아래는 튜토리얼과 자세한 설명이 있는 Docs url이다.
Autoencoders
input을 output으로 copy하는 neural network이다. 입력으로 들어온 이미지를 벡터로 encoding한 후, 이미지로 decoding한다.
Local Environment
Tutorial 코드는 Colab에서 편하게 돌려볼 수 있다. Colab을 이용하면 GPU, TPU 등의 리소스를 빌려서 사용할 수 있다. 그래도 혹시나 Local에서 사용할 일이 생길까 싶어서 환경을 세팅했다.
Install python
python 3.9을 사용한다.
virtualenv env -ppython3.9
. env/bin/activate
pip install -r requirements.txt
위 과정을 통해 환경을 분리해서 패키지를 관리할 수 있다. 단순히 pip을 통해 package를 install 하게 되면 global에 패키지가 깔리게 된다. virtualenv를 통해 환경을 분리하면 프로젝트 별로 의존하는 패키지의 버전을 관리하기 편해진다.
Run tutorial code
Tensorflow에서 설명한 autoencoder 코드를 그대로 실행해봤다.
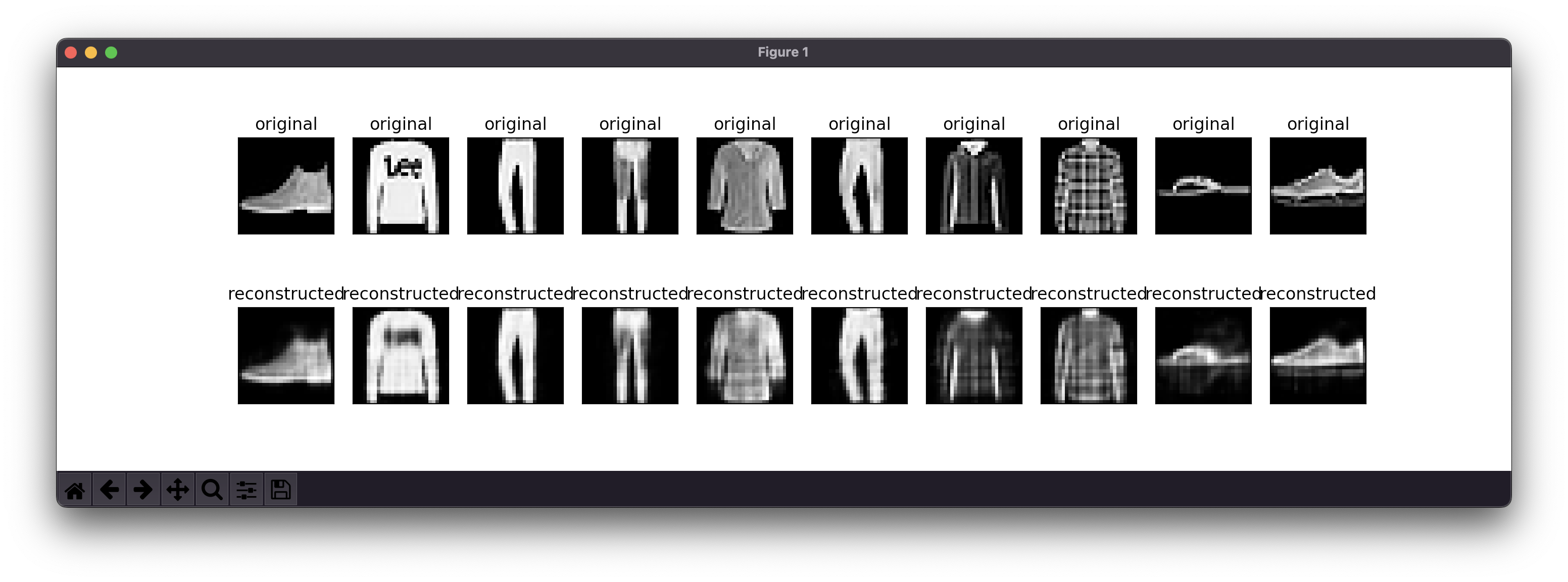
Training AutoEncoder Model in TensorFlow
Tutorial코드를 사용해봤으니, 데모를 만들기 위한 모델을 학습하는 용으로 스크립트를 수정한다.
Prepare data
Tensorflow datasets를 통해서 Tensorflow가 제공하는 Datasets를 편하게 사용할 수 있다. Catalog에서 사용하고자 하는 dataset의 스펙을 확인할 수 있음으로 사용 시 참고하면 된다.
from tensorflow.keras.datasets import fashion_mnist
(x_train, _), (x_test, _) = fashion_mnist.load_data()
Tutorial에서는 data load를 위와 같이 작성한다. temsorflow.kera.datasets은 debugging/testing용으로 제공되는 작은 NumPy datasets이다. 원하는 dataset을 자유롭게 가져오기 위해 아래와 같이 변경한다.
import tensorflow_datasets as tfds
[train_ds, test_ds], ds_info = tfds.load('cifar100', split=['train', 'test'], shuffle_files=True, with_info=True)
굳이 최신 정보로 가져올 필요는 없기 때문에 tensorflow-datasets을 이용한다.
load는 다양한 옵션을 원하는대로 줄 수 있다. shuffle_files은 각 epoch간에 파일을 섞는 여부, with_info는 데이터를 보기 좋게 print하기 위한 tfds.core.DatasetInfo반환 여부를 설정한다.
사용할 dataset을 결정하기 전에 Catalog에서 스팩을 확인해야한다. 확인해보면, cifar100은 label이 있는 사진 6만장을 가지고 있는 dataset이다. 이 dataset의 이미지는 적당한 사이즈(32px * 32px)에 컬러 채널을 가지고 있다. test와 train Example을 가지고 있고, 적당한 개수여서 학습에 적절해보인다.
이 dataset을 사용하기로 결정했으니 load에 dataset의 name을 넘기고 위에서 말한 옵션을 주어 로드한다. train과 test가 적절히 나뉘어진 set이니 split으로 데이터를 분할해준다.
def map_fn(x: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
image = x['image']
image = tf.cast(image, tf.float32)
image /= 256.0
return image, image
train_ds = (
train_ds
.shuffle(ds_info.splits['train'].num_examples, reshuffle_each_iteration=True)
.map(map_fn)
.batch(32)
)
test_ds = (
test_ds
.map(map_fn)
.batch(32)
)
하나의 픽셀 채널은 0~255 범위의 데이터를 가지고 있는데, 이를 0~1의 float 값으로 매핑했다. 그대로 값을 사용하면 activation function을 sigmoid(0~1)를 사용하고 있어서 정상적으로 학습이 진행되지 않는다.
학습 dataset은 각 interation마다 shuffle하도록 설정할 수 있다. batch 사이즈는 임의로 32로 줬다. 여기서 사용한 method는 tf.data.Dataset 문서에서 확인할 수 있다.
Define model
class Autoencoder(tf.keras.Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.Conv2D(32, 3, padding='same', data_format='channels_last'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(latent_dim, activation='relu'),
],
name='encoder',
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.Dense(3072, activation='sigmoid'),
tf.keras.layers.Reshape((32, 32, 3))
],
name='decoder',
)
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
encoder는 image를 input으로 받고 196(latent_dim) dimensional의 latent vector을 출력한다. decoder는 encoding된 데이터를 32*32 사이즈의 3채널 이미지로 출력한다.
Train model
지금까지 정의한 model을 생성하고 직접 학습시킨다.
latent_dim = 196
model = Autoencoder(latent_dim)
model(tf.keras.Input((32, 32, 3)))
model.summary()
Autoencoder 모델을 생성한 후, model에게 Input을 보냄으로 computational graph가 어떻게 생겼는지 알린다. model.summary는 model에 대한 info를 보기 좋게 출력해준다. 지금까지 만든 모델의 출력 결과는 아래와 같다.
Model: "autoencoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoder (Sequential) (None, 196) 6423620
decoder (Sequential) (None, 32, 32, 3) 605184
=================================================================
Total params: 7,028,804
Trainable params: 7,028,804
Non-trainable params: 0
_________________________________________________________________
보통 decoder의 파라미터가 더 많다고 한다. decoder 기능을 개선한 후 나중에 비교해보면 차이를 알 수 있을 것 같다.
model.compile(optimizer='adam', loss=tf.keras.losses.MeanSquaredError())
model.fit(train_ds,
epochs=10,
validation_data=test_ds)
model.compile()로 optimizer, loss function과 matrics을 지정할 수 있다. Tutorial에서 적용한 옵션값을 그대로 사용했다.
fit이 실질적으로 train을 지시하는 부분이다. input data, epoch 수, 검증 data를 통해 학습을 진행한다.
Epoch 1/10
1563/1563 [==============================] - 25s 9ms/step - loss: 0.0173 - val_loss: 0.0113
Epoch 2/10
1563/1563 [==============================] - 9s 5ms/step - loss: 0.0098 - val_loss: 0.0091
Epoch 3/10
1563/1563 [==============================] - 9s 6ms/step - loss: 0.0084 - val_loss: 0.0080
...
Epoch 9/10
1563/1563 [==============================] - 9s 5ms/step - loss: 0.0055 - val_loss: 0.0055
Epoch 10/10
1563/1563 [==============================] - 9s 5ms/step - loss: 0.0053 - val_loss: 0.0053
위와 같이 Epoch 별로 소요된 시간과 loss이 출력된다.
Visualize results
결과는 아래처럼 나왔다.

튜토리얼 모델과 비교해보면 잘 복원하고 있는 중이다.
