Stable diffusion을 이용해서 내 작업을 시키고 싶어졌다. Fine tuning을 할 건데, 효율을 위해 LoRA를 사용한다.
LoRA
Low-Rank Adaptation of Large Language Models(LoRA)는 pretrained 모델의 weights를 고정하고, 그 위에 새로운 task를 위한 weights를 추가하는 방식으로 fine tuning을 진행한다. 이 방식은 Trainable한 parameter의 수를 크게 줄여, 기존의 fine tuning 방식보다 훨씬 빠르다. 또한, 기존의 fine tuning 방식은 모든 weights를 업데이트하는데 반해, LoRA는 일부 weights만 업데이트하기 때문에, 기존의 fine tuning 방식보다 더 적은 양의 데이터로 fine tuning을 할 수 있다.
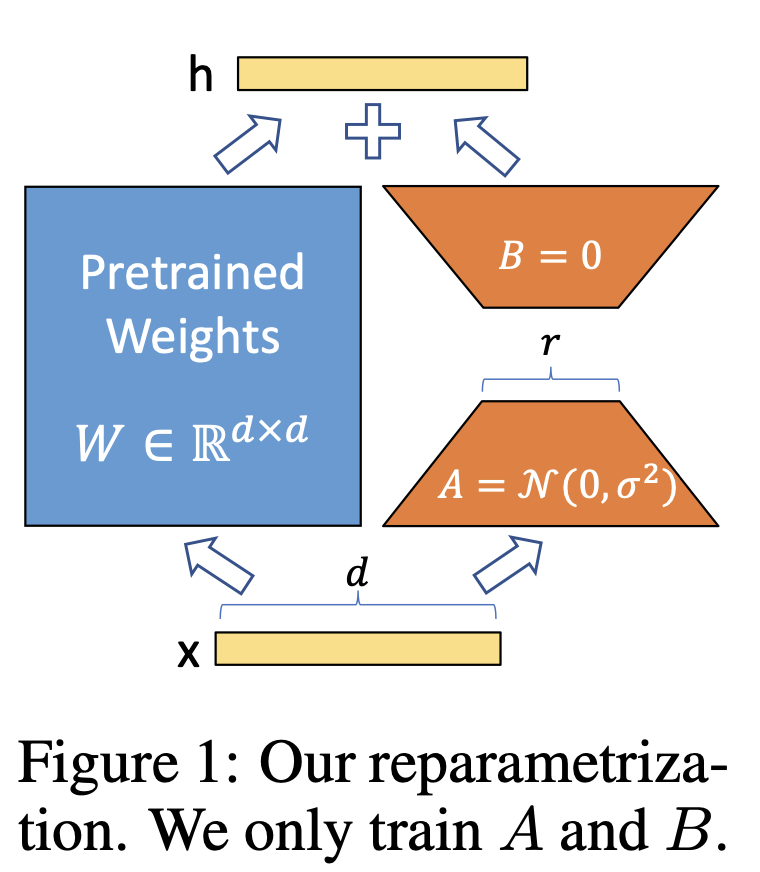
LoRA를 이용하면, 각 task 별로, pretrained 모델에 얹을 task specific한 파라미터 조금만 저장 및 로드하면 된다. 다른 말로, pretrained 모델은 공유하고, 작은 LoRA module을 task 별로 빌드할 수 있다. 이를 통해 용량과 스위칭에 드는 비용을 아낄 수 있다.
대부분의 파라미터에 대해서 gradient 계산이나 최적화가 필요없고, inject한 적은 양의 low rank matrices만 최적화해주면된다.
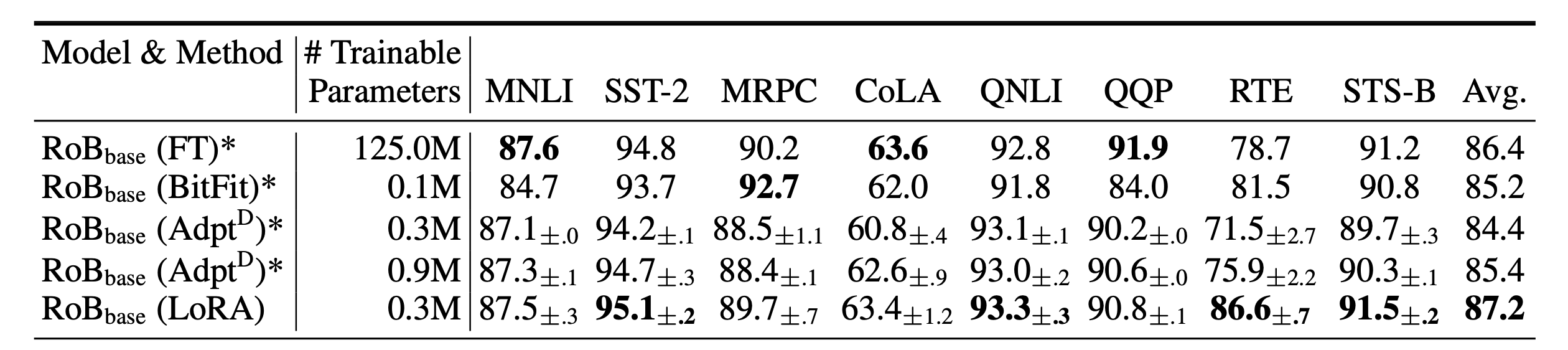
(참고: RoBERTa는 자연어 모델 BERT을 개선하여 pretraining한 모델)
여기서 보면 Trainable Parameters 수가 나온다. 용량과 직결되는 부분인데, LoRA는 FT(Fine-Tuning)의 0.24%인 것을 확인할 수 있다.
논문에서 stress 테스트의 최대치로 GPT-3(175B)까지 확인하는데, Acc가 다른 모델에 비해 높게 나온다.
환경 준비
하드웨어 성능이 안 따라주기 때문에 Colab을 사용한다. 노트북 포맷을 이용해서 GPU를 빌려서 쓴다. 정말 감사하다.🤣 Colab에서 CUDA GPU를 쓰려면 런타임에서 할당해줘야하니 사용이 불가한 상황을 마주하면 확인해보자.
데이터나 노트북 관리는 초반엔 드라이브를 마운트해서 사용하다가, git으로 옮겼다. 이미지 관리가 드라이브를 쓰기엔 불편하기 그지없었다. deploy key 할당해서 쓰는 경험이 처음이라 도움을 좀 받았다.
드라이브에 ssh private 키를 두고, clone 받을 때 가져와서 쓰는 방식으로 했다. 드라이브를 아예 안 쓸 수는 없었다.
파인 튜닝
GitHub: Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning 사용법은 이 깃헙에 잘 나와있다. 여기서 소개한 사용법을 거의 그대로 사용했다. Text-to-Image Diffusion 파인 튜닝을 위한 LoRA 구현이다.
pretrained model은 runwayml/stable-diffusion-v1-5을 사용했다.
!lora_pti \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--instance_data_dir="$INSTANCE_DIR \
--output_dir=$OUTPUT \
--train_text_encoder \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--scale_lr \
--learning_rate_unet=1e-4 \
--learning_rate_text=1e-5 \
--learning_rate_ti=5e-4 \
--color_jitter \
--lr_scheduler="linear" \
--lr_warmup_steps=0 \
--placeholder_tokens="<s1>|<s2>" \
--placeholder_token_at_data="<tok>|<s1><s2>" \
--save_steps=100 \
--max_train_steps_ti=1000 \
--max_train_steps_tuning=1000 \
--perform_inversion=True \
--clip_ti_decay \
--weight_decay_ti=0.000 \
--weight_decay_lora=0.001\
--continue_inversion \
--continue_inversion_lr=1e-4 \
--device="cuda:0" \
--lora_rank=1
# --use_face_segmentation_condition\
각 옵션은 역할을 좀 더 파악하고 손을 대볼 필요가 있다. 실행하면 각 스텝별로 .safetensor 파일이 output 경로로 떨어진다.
safetensor는 tensor를 저장하는 포맷이다. 즉, matrices, 즉, weights를 저장한다. 이걸 그대로 사용할 순 없고 pretrained model에 적용해서 써야한다. 그 방법은 아래와 같다.
결과 weights 사용하기
“Tutorial : Running minimal inference examples with diffuser.” 문서를 참고한다.
from diffusers import StableDiffusionPipeline, EulerAncestralDiscreteScheduler
import torch
from lora_diffusion import tune_lora_scale, patch_pipe
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16).to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
def patch(path="./output/final_lora.safetensors", unet_scale=1.0, text_scale=1.0):
patch_pipe(
pipe,
path,
patch_text=True,
patch_ti=True,
patch_unet=True,
)
tune_lora_scale(pipe.unet, unet_scale)
tune_lora_scale(pipe.text_encoder, text_scale)
def run(prompt, **kwargs):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = 50
if "guidance_scale" not in kwargs:
kwargs["guidance_scale"] = 7
return pipe(prompt, num_inference_steps=50, guidance_scale=7).images
patch()
tune_lora_scale를 이용해서 weights를 적용한다.
이렇게 하고 run에 prompt를 넣어주면 되겠다.
데이터셋
데이터셋을 보지 않으면 결과물 가늠이 안가니 먼저 소개한다. 레이블에 쓴 <tok>는 LoRA discussion를 참고.
인스타툰


총 22장이다. 영혼까지 긁어모아서 몇 장은 그림체가 살짝 다르다.
스케치


총 19장이다. 성별이 뒤죽박죽인데 그림체가 워낙 어려보이게 그리기도 해서, BLIP이 적어준대로 썼다.
결과물
Fine-Tuning한 결과물을 적당히 정리한다. 1차 결과물이고 앞으로 개선해나간다. 정말로 인스타툰을 대신 시키고 싶다.
인스타툰
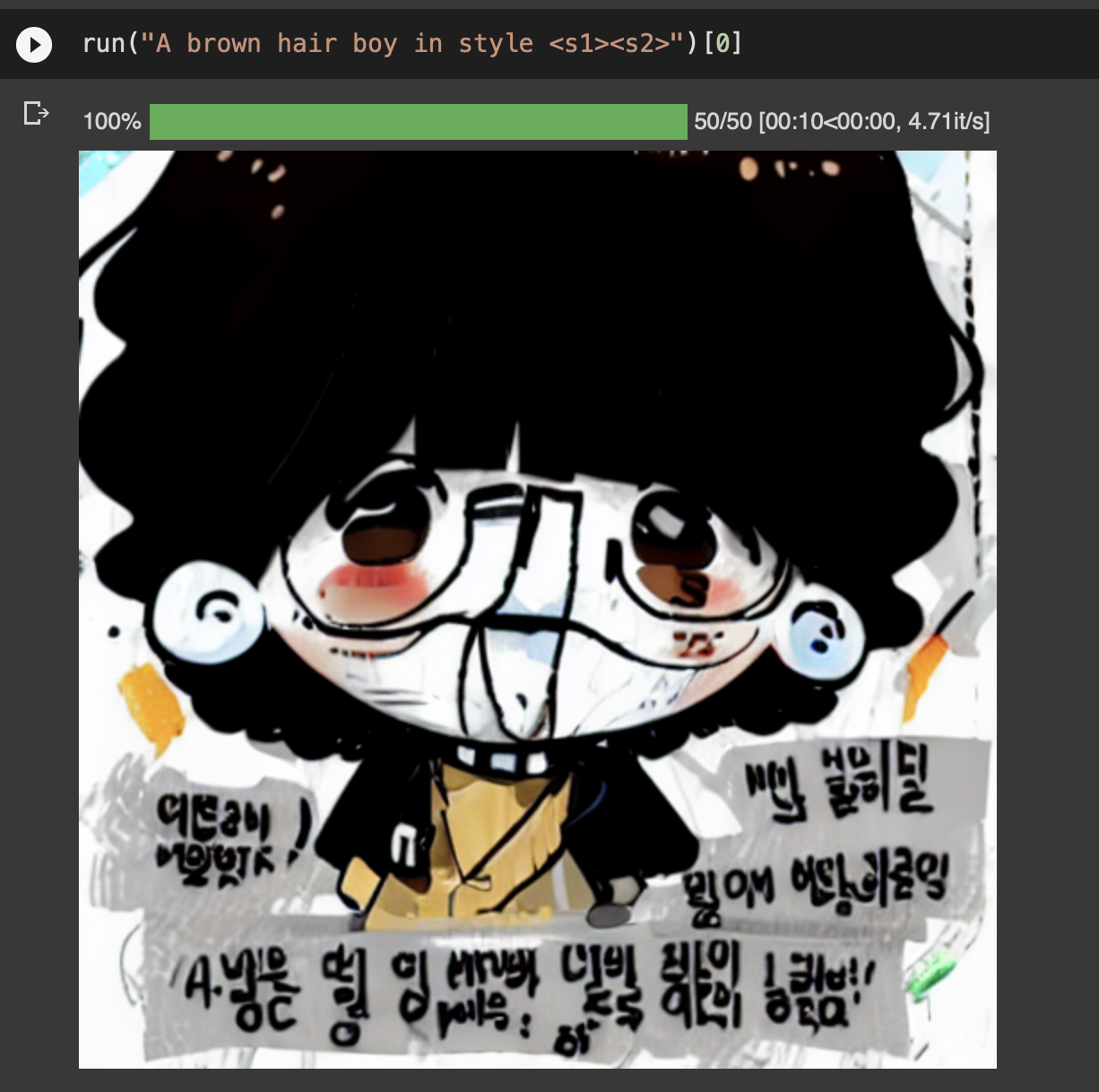

이 때 쓴 데이터에는 인스타툰의 효과음, 말풍선 등이 모두 들어갔었는데 글자를 너무 열심히 생성하길래 전부 지워줘야했다.
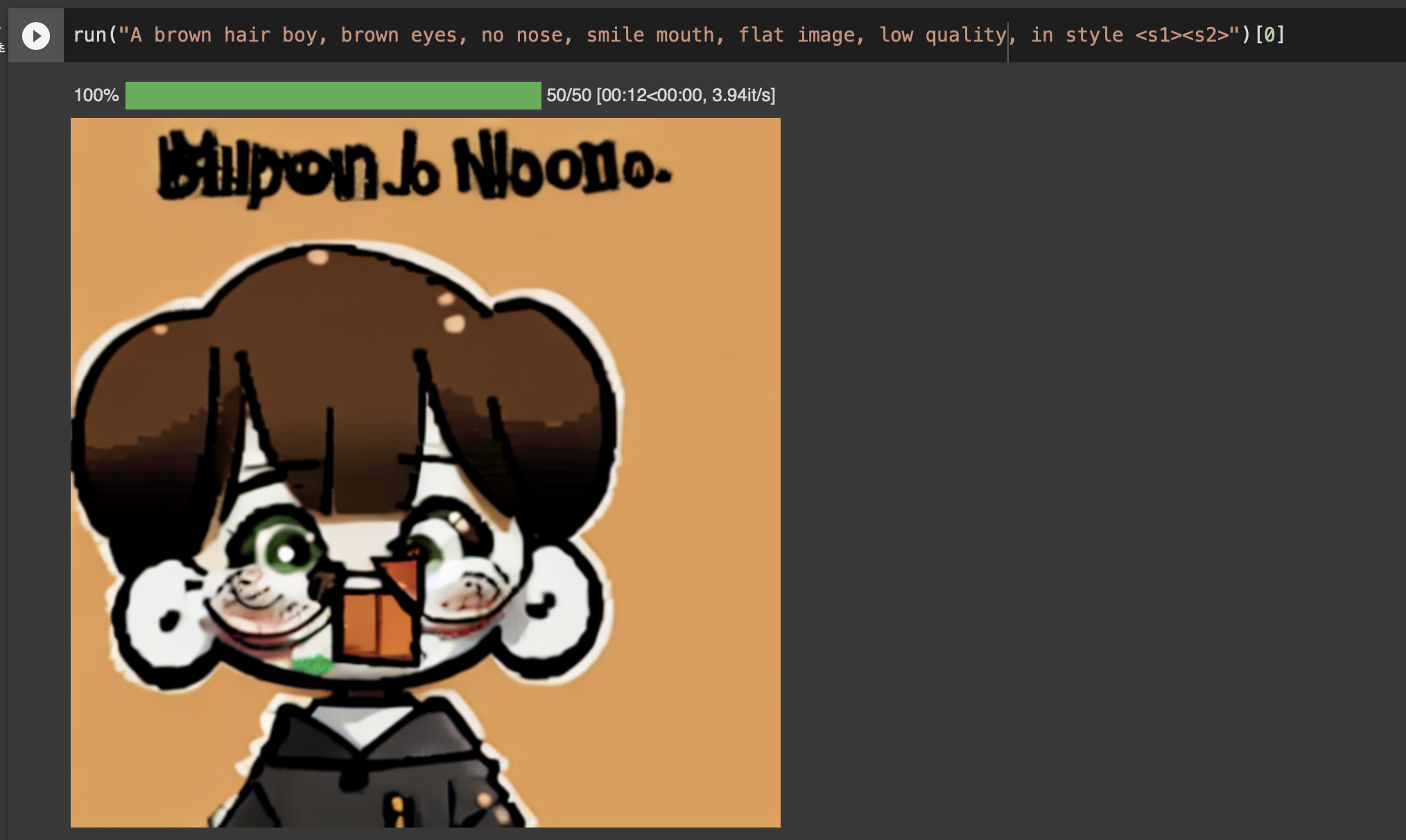

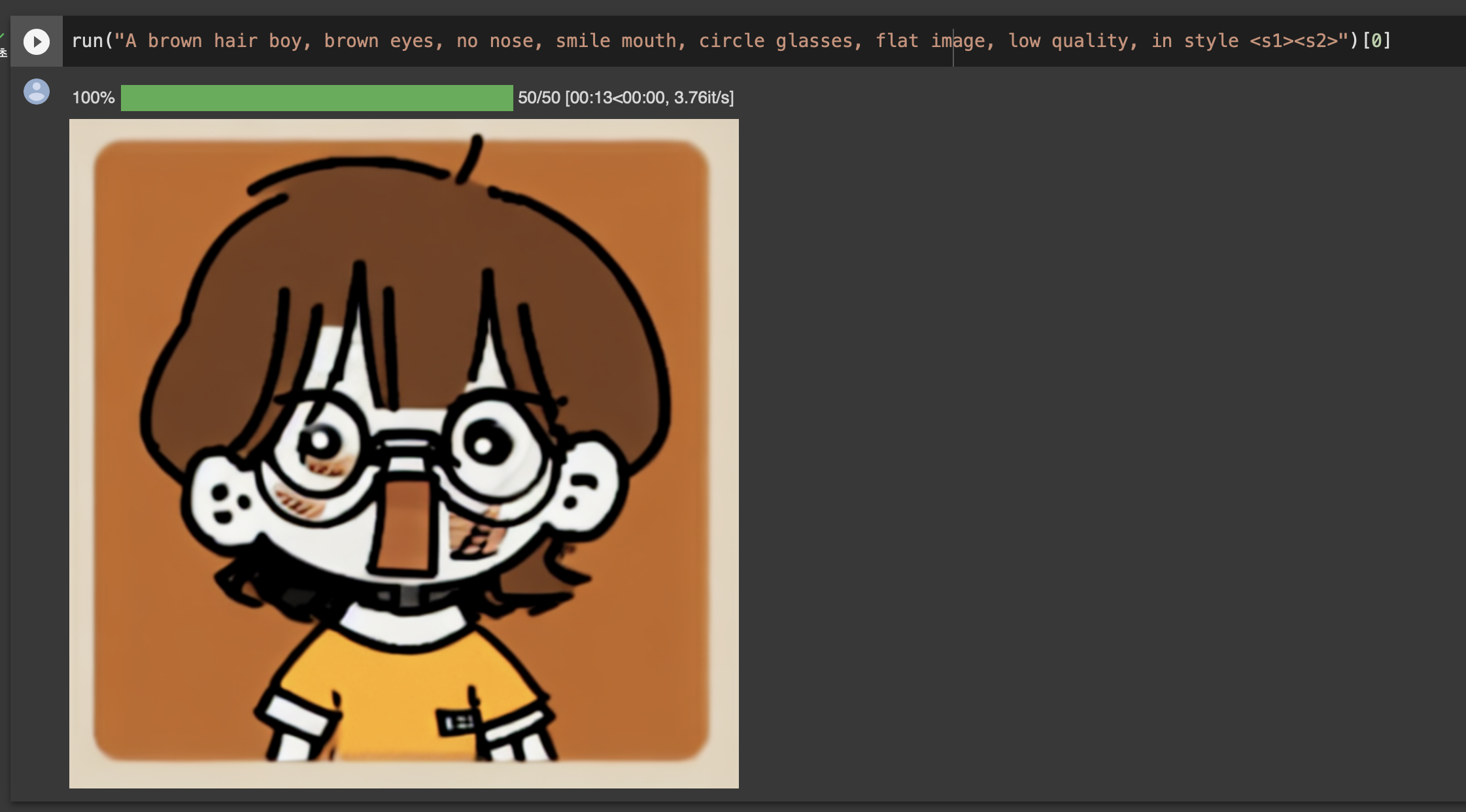
데이터를 더 넣고 레이블을 손보면 더 나은 결과물이 나올 것 같다. 프롬프트도 조금 익숙해져야할 것 같다.
스케치
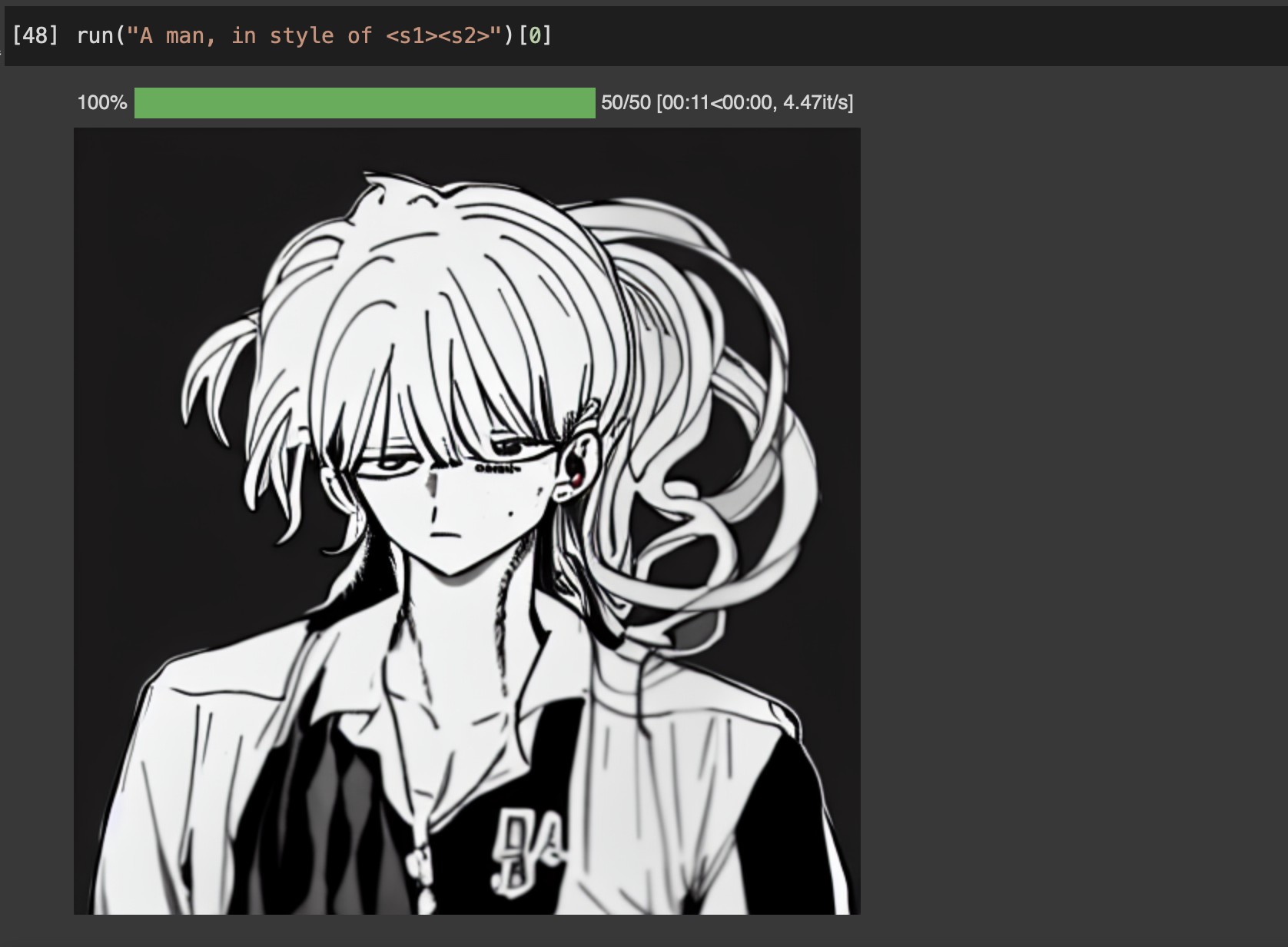
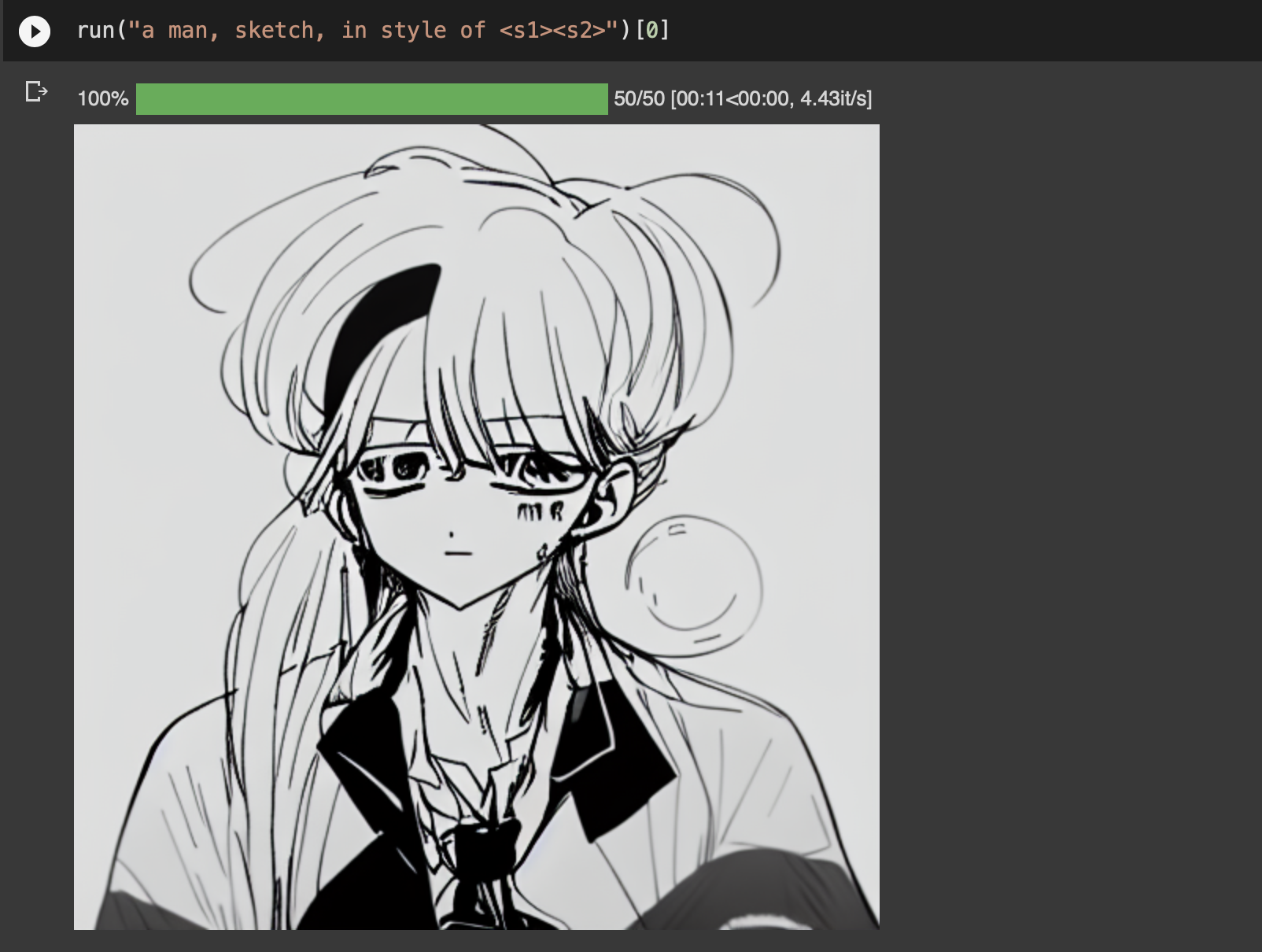
스케치도 마찬가지. 데이터를 더 넣고 레이블을 손보면 결과물이 나아질 것 같다.
TODO
스케치와 인스타툰 데이터는 적고 실험용이어서 BLIP으로 labeling 후, 손으로 수정해줬지만 일러스트 폴더는 그렇지 않다. 언제까지고 손으로 할 수는 없는 노릇이니 조금 더 좋은 labeling 방식이 필요하다. 그런 이유로, BLIP2가 성능이 좋다고 해서 시도해볼까 한다.