
Overview
Gradio는 ML 데모 앱을 만들 수 있는 python 라이브러리다. 웹용 데모를 만드는 데에 특화되어있다. 웹의 장점을 그대로 안고 갈 수 있다. 데모용으로 배포가 쉽고 구현이 빠르다.
당연히 프로덕트로는 부족하겠지만, 툴로 사용하기 좋다. 최종 결과물을 뱉는 용도보다는 중간 결과물, 혹은 아이디어 제조기로 쓸 수 있겠다. Docs가 꽤 꼼꼼하게 정리되어있어서 참고하기 좋기 때문에 이 참에 훑고 지나간다.
머신 러닝 개념은 전에 정리한 자료가 여기에 있으니 참고.
환경 세팅
python3.9를 사용했다. 모두 Global로 관리할 수는 없기 때문에 환경 세팅을 해줘야한다. 아래로 간단하게 세팅에 대해 메모한다.
pyenv
python은 버전에 예민한 언어이기 때문에 pyenv를 이용해서 버전 관리를 해줄 수 있다. 레포에 설치방법이 자세히 나와있으니 그대로 하면된다.
셸에서 python, pip 등 python 관련 커맨드를 실행하게 되면, PATH에 등록된 경로를 순회하며 커맨드를 찾는다. 이 때 pyenv가 깔려있다면 python에 관련된 키워드를 인터셉트하여 동일한 이름의 pyenv shim을 실행한다. 이를 통해 명령을 전달받은 pyenv가 어플리케이션에 필요한 버전의 python을 넘겨주는 것이다.
virtualenv
설치 및 세팅은 virtualenv docs를 참고하면 되고, 간단하게 아래와 같이 한다.
pip{VERSION} install virtualenv
virtualenv는 global이 아닌, 독립된 python 환경을 조성할 수 있게 한다. 각 어플리케이션이 사용하는 패키지의 버전이 다를 수도 있고, dependency를 예민하게 관리해줘야할 경우도 생길 수 있는데, 이런 식으로 환경을 나눈다면 현재 어플리케이션만 고려할 수 있어서 편하다.
virtualenv env -ppython{VERSION}
env라는 디렉토리가 생겼다. 앞으로 다운받는 패키지는 이 하위로 들어간다. 활성화는 아래와 같이 한다.
. env/bin/activate
그럼 터미널이 (env) ➜ gradio-playground git:(main) ✗ 이런 식으로 바뀌는 것을 확인할 수 있다.
requirements
이제 pip으로 패키지를 받으면 env 아래로 붙는다. 여기서 좀 당황했는데, 따로 패키지 file이 떨어지지 않아서 dependency 명시를 할 방법을 따로 찾아야했다.
requirements.txt에 사용할 패키지 명을 명시하면 되고, 이 블로그에서 잘 설명해주니 참고하면 되겠다.
pip install -r requirements.txt
위 커맨드로 requirements.txt의 패키지를 일괄 받을 수 있다.
Gradio 사용
Gradio의 interface class는 python function을 UI와 함께 래핑한다. 아래가 많이 쓰는 구성이다.
- fn: 실행할 함수
- inputs: input을 받을 때 사용할 컴포넌트 혹은 컴포넌트 배열
- outputs: output을 받을 때 사용할 컴포넌트 혹은 컴포넌트 배열
- examples: input에 넣어볼 수 있는 예시 혹은 예시 배열
interface대신 block을 사용할 수도 있다. interface가 high-level이라면, block은 low-level API며, 보다 더 자유롭게 구성할 수 있다. 그러나 예시에선 Interface를 기본으로 사용하고 있고, 굳이 꾸밀 필요는 없기 때문에 Interface를 쓰는 편이 더 편해보인다.
프로세스
Gradio pre, post processing이 이뤄지는 순서는 이렇다.

사용하려는 모델이 요구하는 input과 output 형태, activation function 종류 정도만 알면 바로 사용할 수 있겠다.
example
예시라고 해봤자… launch 스크립트 하나가 전부다. 나눠서 간단하게 설명한다. 사용할 모델은 smilegate의 UnSmile이라는 혐오 분류 모델이다.
def checkHateSpeech(text):
with torch.no_grad():
inputs = tokenizer(text, return_tensors="pt") # 'pt' means Pytorch
outputs = model(**inputs)
logits = outputs["logits"]
probs = torch.sigmoid(logits)
probs_by_labels = {labels[i]: float(probs[0][i]) for i in range(len(labels))}
return probs_by_labels
분류 함수는 speech에 해당하는 문자열 하나만 받아오면 된다.
torch.no_grad()는 gradient를 사용하지 않겠다는 선언이다. gradient 과정은 메모리와 시간을 잡아먹기 때문에 사용하지 않을 때 위 처럼 명시해줘야한다. 명시하지 않으면 기본적으로 gradient 연산이 들어간다. 자세한 건 no_grad문서를 참고.
SequenceClassifierOutput(loss=None, logits=tensor([[ 3.1481, -4.7705, -6.1901, -4.7506, -5.0350, -5.1771, -6.1920, -4.2019, -5.4408, -5.7670]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
output은 위와 같고, Gradio의 Label에게 넘겨줄 때는 label:value 맵으로 넘겨줘야해서 약간의 가공 과정이 들어갔다. 원하면 단순히 output을 텍스트로 뱉어도 된다.
gr.Interface(
fn=checkHateSpeech,
inputs=gr.Textbox(label="Text"),
outputs=gr.Label(
label="Output Box (multi-label classification)", num_top_classes=5
),
examples=[
"사랑해요~",
# others...
],
).launch()
위 코드 하나로 UI, 기능 연결 그리고 로컬 서버 띄우기까지 해결할 수 있다. 이게 바로 Gradio의 강점이다. output은 gr.Label로 각 lable에 대한 비주얼라이즈가 가능하다. multi label 모델이기 떄문에 여러 label을 노출해야하고, 텍스트 보다는 차트가 보기 편하기 때문에 써봤다.
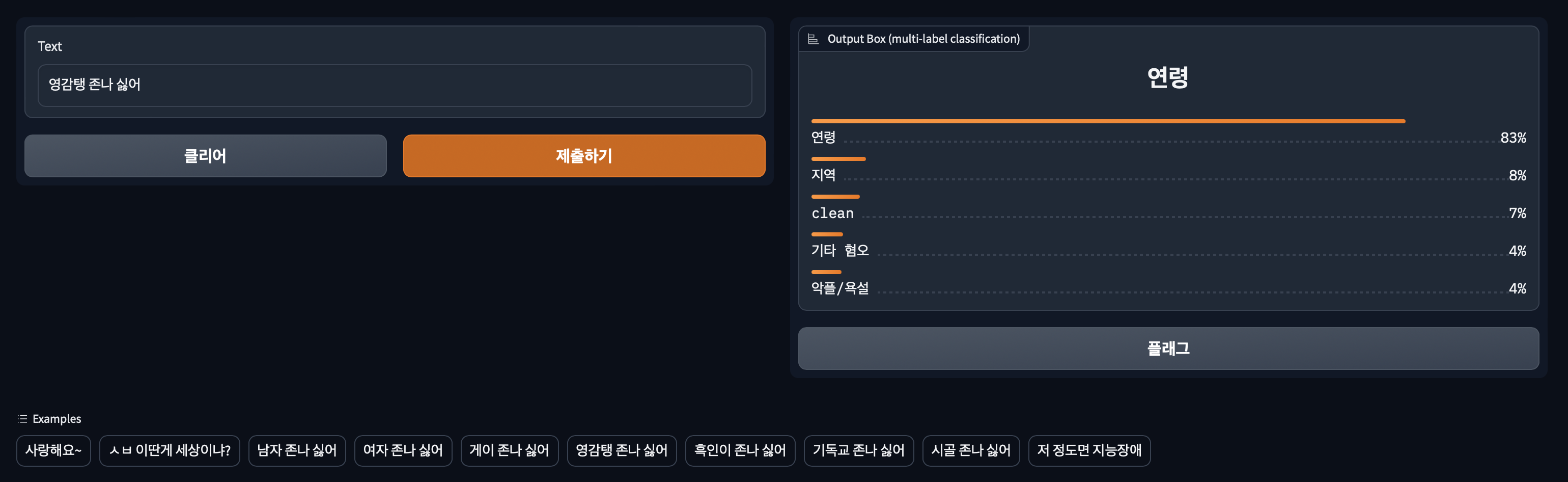
결과 화면은 이렇다.
후기
요즘에는 나와있는 model도 많고, 이렇게 쉽게 데모 페이지를 만들 수 있는 툴도 있다. ml이 점점 더 쉽게 접할 수 있는 만큼 더 바짝 따라가야겠다는 생각이 든다. 간단하게나마 맛볼 수 있어서 좋은 기회였던 것 같다.